<?xml version="1.0" encoding="utf-8" ?>
<booklist>
<book id="b1" kind="컴퓨터">
<title>기초에서 실무까지 XML</title>
<author>신민철</author>
<publisher>프리렉</publisher>
<price>35000</price>
</book>
<book id="b2" kind="소설">
<title>사랑과 전쟁</title>
<author>이사랑</author>
<publisher>전쟁문화사</publisher>
<price>15000</price>
</book>
<book id="b3" kind="잡지">
<title>마이크로 소프트</title>
<author>빌 게이츠</author>
<publisher>마소문화사</publisher>
<price>20000</price>
</book>
<book id="b4" kind="소설">
<title>액션가면부인 바람났네</title>
<author>짱구</author>
<publisher>짱구출판사</publisher>
<price>12000</price>
</book>
</booklist>
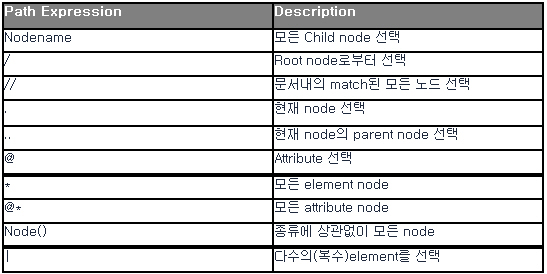
이번 예제는 XmlAttributeCollection을 이용해 element에 속한 attribute를 collection으로 가져와서 loop를 이용해 출력하는 예제를보여준다.
using System;
using System.Linq;
using System.Collections.Generic;
using System.Text;using System.Xml;
namespace CH11
{
class p559_FindAttribute
{
static void Main()
{
string filePath = @"..\..\booklist.xml";
XmlDocument xDoc = new XmlDocument();
xDoc.Load(filePath);XmlElement eBook = xDoc.DocumentElement;
XmlElement eFirstBook = (XmlElement)eBook.FirstChild;XmlAttributeCollection attributes = eFirstBook.Attributes;
// loop를 이용한 attribute 탐색
for (int i = 0; i < attributes.Count; i++)
{
XmlAttribute attribute = (XmlAttribute)attributes[i];
Console.WriteLine(attribute.Name + "\t" + attribute.Value);
}// 직접 attribute 출력
string id = eFirstBook.GetAttribute("id");
Console.WriteLine("id:\t" + id);string kind = eFirstBook.GetAttribute("kind");
Console.WriteLine("kind:\t" + kind);
}
}
}
attribute를 탐색할때 위 예제와 같이 활용하면 되겠다.
ref. .NET 닷넷 개발자를 위한 XML p.559